A tiny simulation
This is a self-contained example. No outside dataset required.
Data generation
[1]:
from functools import reduce
import pickle as pkl
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.metrics
[2]:
import matplotlib
matplotlib.rcParams['mathtext.fontset'] = 'dejavuserif'
matplotlib.rcParams['font.family'] = 'arial'
matplotlib.rc('pdf', fonttype=42)
do_savefig = False
savefig_path = './'
[3]:
np.random.seed(42)
## Create a grid
width = 50
height = 8
xs = np.arange(0, width)
ys = np.arange(0, height)
grid_x, grid_y = np.meshgrid(xs, ys)
grid_x = grid_x.ravel()
grid_y = grid_y.ravel()
df = pd.DataFrame(np.array([grid_x, grid_y]).T,
columns=['x', 'y'],
index=reduce(np.char.add, ['cell_', grid_x.astype(str), '_', grid_y.astype(str)]))
## Randomly assign cell types
for y in range(3, 8):
random_columns = np.random.choice([0, 1, 2], width, p=[0.3, 0.3, 0.4])
df.loc[(random_columns[df['x']] == 0) & (df['y'] == y), 'celltype'] = 'B'
df.loc[(random_columns[df['x']] == 1) & (df['y'] == y), 'celltype'] = 'C'
df.loc[(random_columns[df['x']] == 2) & (df['y'] == y), 'celltype'] = 'D'
df.loc[(df['y'] <= 2), 'celltype'] = 'A'
## Generate receptor expression
def go(d, x, y, width, height):
if d == 'left':
x = x - 1
elif d == 'right':
x = x + 1
elif d == 'up':
y = y + 1
elif d == 'down':
y = y - 1
elif d == 'left-up':
x = x - 1
y = y + 1
elif d == 'right-up':
x = x + 1
y = y + 1
elif d == 'left-down':
x = x - 1
y = y - 1
elif d == 'right-down':
x = x + 1
y = y - 1
if x < 0 or y < 0 or x >= width or y >= height:
return None, None
else:
return x, y
df['R+'] = 0
for i in df.index:
if df.loc[i, 'celltype'] in ['B', 'C']:
for d in ['left', 'right', 'up', 'down', 'left-up', 'right-up', 'left-down', 'right-down']:
x, y = go(d, df.loc[i, 'x'], df.loc[i, 'y'], width, height)
if x is not None and y is not None:
j = f'cell_{x}_{y}'
if df.loc[j, 'celltype'] == 'A':
if np.random.rand() < 1.:
df.loc[i, 'R+'] = 1
meta_expr_split = df.shape[1] # Number of columns for metadata, the rest is "expression"
# Housekeeping genes that are uniform over all cell types
df['H1'] = 50
df['H2'] = 50
df['H3'] = 50
df['H4'] = 50
# Cell identity genes that are over expressed in the corresponding cell type
df['A1'] = 1
df['A2'] = 1
df['B1'] = 1
df['B2'] = 1
df['C1'] = 1
df['C2'] = 1
df['D1'] = 1
df['D2'] = 1
df.loc[df['celltype'] == 'A', 'A1'] = 50
df.loc[df['celltype'] == 'A', 'A2'] = 50
df.loc[df['celltype'] == 'B', 'B1'] = 50
df.loc[df['celltype'] == 'B', 'B2'] = 50
df.loc[df['celltype'] == 'C', 'C1'] = 50
df.loc[df['celltype'] == 'C', 'C2'] = 50
df.loc[df['celltype'] == 'D', 'D1'] = 50
df.loc[df['celltype'] == 'D', 'D2'] = 50
# LR
df['R'] = 1
df.loc[:, 'R'] = 100 * df['R+']
features = df.columns[meta_expr_split:].tolist()
print(*features)
expr = np.random.poisson(df[features])
expr = pd.DataFrame(expr, index=df.index, columns=features)
expr[['H1', 'H2', 'H3', 'H4']] = 50
H1 H2 H3 H4 A1 A2 B1 B2 C1 C2 D1 D2 R
[4]:
meta = df.iloc[:, :meta_expr_split]
Run Steamboat
Prepare the dataset
[5]:
import os
import sys
import pickle as pkl
import matplotlib.pyplot as plt
## Add path to the directory containing steamboat.
sys.path.append("../")
import torch
import pandas as pd
import numpy as np
import scipy as sp
import scanpy as sc
import squidpy as sq
import steamboat as sf # Steamboat Factorization -> sf
import steamboat.tools
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\dask\dataframe\_pyarrow_compat.py:15: FutureWarning: Minimal version of pyarrow will soon be increased to 14.0.1. You are using 11.0.0. Please consider upgrading.
warnings.warn(
[6]:
device = "cuda"
[7]:
adata = sc.AnnData(expr, obs=meta)
adata.obsm['spatial'] = np.array(meta[['x', 'y']])
adata.obs['global'] = 0
adata
adatas = [adata] # You can include multiple datasets here.
adatas = sf.prep_adatas(adatas)
dataset = sf.make_dataset(adatas, regional_obs=[])
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\anndata\utils.py:292: UserWarning: X converted to numpy array with dtype int64
warnings.warn(f"{name} converted to numpy array with dtype {arr.dtype}")
Using [] as regional annotations.
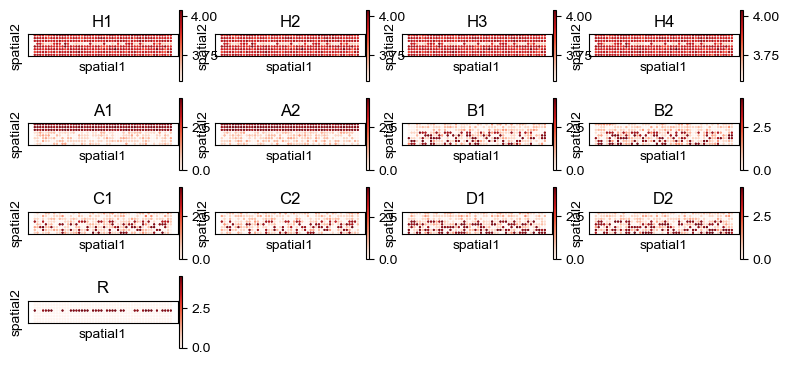
[8]:
sq.pl.spatial_scatter(adatas[0], color=adatas[0].var_names, shape=None, figsize=(2, 1), size=1.,
legend_fontsize=9, cmap='Reds', ncols=4)
WARNING: Please specify a valid `library_id` or set it permanently in `adata.uns['spatial']`
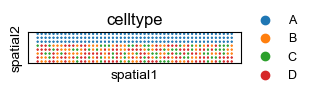
[9]:
sq.pl.spatial_scatter(adatas[0], color='celltype', shape=None, figsize=(3, 2), size=1.,
legend_fontsize=9, cmap='Reds', ncols=4)
WARNING: Please specify a valid `library_id` or set it permanently in `adata.uns['spatial']`
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\squidpy\pl\_spatial_utils.py:946: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap', 'norm' will be ignored
_cax = scatter(
[10]:
sq.pl.spatial_scatter(adatas[0], color='R', shape=None, figsize=(3, 2), size=1.,
legend_fontsize=9, cmap='Reds', ncols=4)
WARNING: Please specify a valid `library_id` or set it permanently in `adata.uns['spatial']`
Train and inspect the metagenes
[11]:
sf.set_random_seed(2)
model = sf.Steamboat(adata.var_names.tolist(), n_heads=5, n_scales=2)
model = model.to(device)
model.fit(dataset, entry_masking_rate=0.2, feature_masking_rate=0.2,
max_epoch=10000,
loss_fun=torch.nn.MSELoss(reduction='sum'),
opt=torch.optim.Adam, opt_args=dict(lr=0.01), stop_eps=1e-3, report_per=200, stop_tol=1000, device=device)
[2025-03-04 15:18:31,216::train::INFO] Epoch 1: train_loss 93.53722
[2025-03-04 15:18:31,833::train::INFO] Epoch 201: train_loss 45.86432
[2025-03-04 15:18:32,414::train::INFO] Epoch 401: train_loss 18.05071
[2025-03-04 15:18:33,002::train::INFO] Epoch 601: train_loss 15.25431
[2025-03-04 15:18:33,632::train::INFO] Epoch 801: train_loss 14.48488
[2025-03-04 15:18:34,306::train::INFO] Epoch 1001: train_loss 13.66049
[2025-03-04 15:18:34,900::train::INFO] Epoch 1201: train_loss 13.85075
[2025-03-04 15:18:35,461::train::INFO] Epoch 1401: train_loss 8.00697
[2025-03-04 15:18:36,033::train::INFO] Epoch 1601: train_loss 8.28427
[2025-03-04 15:18:36,595::train::INFO] Epoch 1801: train_loss 7.29631
[2025-03-04 15:18:37,155::train::INFO] Epoch 2001: train_loss 6.12441
[2025-03-04 15:18:37,761::train::INFO] Epoch 2201: train_loss 5.56421
[2025-03-04 15:18:38,348::train::INFO] Epoch 2401: train_loss 4.44459
[2025-03-04 15:18:38,954::train::INFO] Epoch 2601: train_loss 23.91569
[2025-03-04 15:18:39,564::train::INFO] Epoch 2801: train_loss 4.39433
[2025-03-04 15:18:40,191::train::INFO] Epoch 3001: train_loss 5.70080
[2025-03-04 15:18:40,833::train::INFO] Epoch 3201: train_loss 4.24723
[2025-03-04 15:18:41,470::train::INFO] Epoch 3401: train_loss 4.25953
[2025-03-04 15:18:42,089::train::INFO] Epoch 3601: train_loss 3.40463
[2025-03-04 15:18:42,697::train::INFO] Epoch 3801: train_loss 8.52747
[2025-03-04 15:18:43,298::train::INFO] Epoch 4001: train_loss 5.92595
[2025-03-04 15:18:43,909::train::INFO] Epoch 4201: train_loss 4.36083
[2025-03-04 15:18:44,600::train::INFO] Epoch 4401: train_loss 3.44769
[2025-03-04 15:18:45,223::train::INFO] Epoch 4601: train_loss 4.07736
[2025-03-04 15:18:45,834::train::INFO] Epoch 4801: train_loss 4.35808
[2025-03-04 15:18:46,438::train::INFO] Epoch 5001: train_loss 5.09088
[2025-03-04 15:18:47,036::train::INFO] Epoch 5201: train_loss 3.47747
[2025-03-04 15:18:47,642::train::INFO] Epoch 5401: train_loss 4.57676
[2025-03-04 15:18:48,258::train::INFO] Epoch 5601: train_loss 4.05396
[2025-03-04 15:18:48,838::train::INFO] Epoch 5792: train_loss 6.33401
[2025-03-04 15:18:48,839::train::INFO] Stopping criterion met.
[11]:
Steamboat(
(spatial_gather): BilinearAttention(
(bias): NonNegBias(
(elu): ELU(alpha=1.0)
)
(q): NonNegLinear(
(elu): ELU(alpha=1.0)
)
(k_local): NonNegLinear(
(elu): ELU(alpha=1.0)
)
(k_regionals): ModuleList()
(w_ego): NonNegScale(
(elu): ELU(alpha=1.0)
)
(tanh): Tanh()
(v): NonNegLinear(
(elu): ELU(alpha=1.0)
)
(cosine_similarity): CosineSimilarity()
)
)
[12]:
sf.tools.plot_all_transforms2(model, top=0)
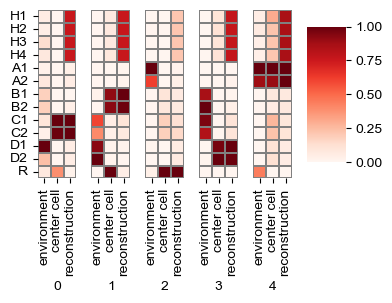
[15]:
# Calculate the embedding, graph, and reconstructed cells (if needed) and store them in obs/obsm/uns
sf.tools.calculate_obs(adatas, dataset, model, get_recon=False)
# For multiple slides, use the following function to gather all obs/obsm/uns of individual slides into the whole AnnData
# sf.tools.gather_obs(adata, adatas)
[16]:
i = 0
quantile = 1 - 0.01
ego = np.quantile(adatas[i].obsm['ego_attn'], quantile, axis=0)
local = np.quantile(adatas[i].obsm['local_attn'], quantile, axis=0)
# regional = np.quantile(adatas[i].obsm['regional_attn_0'], quantile, axis=0)
fig, ax = plt.subplots(figsize=(4, 1))
sns.heatmap(np.vstack([ego, local]) * 100, vmax=50, ax=ax, linewidths=0.2, linecolor='grey', cmap='Reds', annot=True, fmt='.0f')
ax.set_yticklabels(['ego', 'local'], rotation=0)
fig, ax = plt.subplots(figsize=(4, 1))
matrix = np.vstack([ego, local])
matrix /= matrix.sum(axis=0)
sns.heatmap((matrix * 100).round(), vmax=100, ax=ax, linewidths=0.2, linecolor='grey', cmap='Reds', annot=True, fmt='.0f')
ax.set_yticklabels(['ego', 'local'], rotation=0)
[16]:
[Text(0, 0.5, 'ego'), Text(0, 1.5, 'local')]
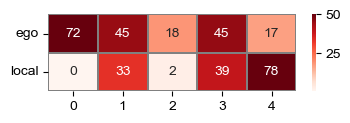
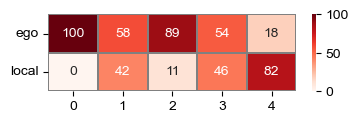
Annotate the adata(s) with the scores
Clustering
[17]:
sf.tools.neighbors(adata, 'attn')
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\umap\distances.py:1063: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
@numba.jit()
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\umap\distances.py:1071: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
@numba.jit()
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\umap\distances.py:1086: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
@numba.jit()
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\umap\umap_.py:660: NumbaDeprecationWarning: The 'nopython' keyword argument was not supplied to the 'numba.jit' decorator. The implicit default value for this argument is currently False, but it will be changed to True in Numba 0.59.0. See https://numba.readthedocs.io/en/stable/reference/deprecation.html#deprecation-of-object-mode-fall-back-behaviour-when-using-jit for details.
@numba.jit()
[18]:
sf.tools.leiden(adata, resolution=0.1)
[19]:
sq.pl.spatial_scatter(adata, color='steamboat_clusters', shape=None, figsize=(3, 2), size=1.,
legend_fontsize=9, cmap='Reds', ncols=4)
if do_savefig:
plt.savefig(savefig_path + 'sim-clusters.pdf')
WARNING: Please specify a valid `library_id` or set it permanently in `adata.uns['spatial']`
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\squidpy\pl\_spatial_utils.py:946: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap', 'norm' will be ignored
_cax = scatter(
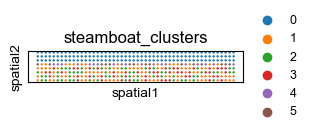
[20]:
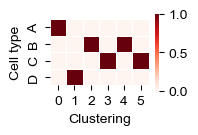
labels=['A', 'B', 'C', 'D', '0', '1', '2', '3', '4', '5']
df = pd.DataFrame(sklearn.metrics.confusion_matrix(adata.obs['celltype'], adata.obs['steamboat_clusters'], labels=labels),
columns=labels, index=labels).loc[['A', 'B', 'C', 'D'], ['0', '1', '2', '3', '4', '5']]
df /= df.sum(axis=0)
fig, ax = plt.subplots(figsize=(1.6, 1.0))
sns.heatmap(df, linewidths=.5, ax=ax, cmap='Reds', square=True)
ax.set_xlabel('Clustering')
ax.set_ylabel('Cell type')
if do_savefig:
plt.savefig(savefig_path + 'sim-clusters-conf.pdf')
Segmentation
[21]:
sf.tools.segment(adata, resolution=0.33)
[22]:
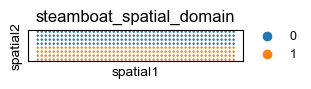
sq.pl.spatial_scatter(adata, color='steamboat_spatial_domain', shape=None, figsize=(3, 2), size=1.,
legend_fontsize=9, cmap='Reds', ncols=4)
if do_savefig:
plt.savefig(savefig_path + 'sim-sd.pdf')
WARNING: Please specify a valid `library_id` or set it permanently in `adata.uns['spatial']`
C:\Users\lshh\miniconda3\envs\py311_torch211_cuda121\Lib\site-packages\squidpy\pl\_spatial_utils.py:946: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap', 'norm' will be ignored
_cax = scatter(
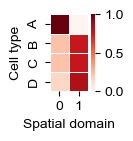
[23]:
labels=['A', 'B', 'C', 'D', '0', '1']
df = pd.DataFrame(sklearn.metrics.confusion_matrix(adata.obs['celltype'], adata.obs['steamboat_spatial_domain'], labels=labels),
columns=labels, index=labels).loc[['A', 'B', 'C', 'D'], ['0', '1']]
df = df.div(df.sum(axis=1), axis=0)
fig, ax = plt.subplots(figsize=(.7, 1.0))
sns.heatmap(df, linewidths=.5, ax=ax, cmap='Reds', square=True)
ax.set_xlabel('Spatial domain')
ax.set_ylabel('Cell type')
plt.savefig('sim-sd-conf.pdf')